
Advanced Machine Learning - Introduction to Deep Learning- Week4
This post is a summary for Advanced Machine Learning - Introduction to Deep Learning Course week4 in Coursera.
Intro to Unsupervised Learning
- Supervised vs Unsupervised
- supervised learnings: Take (x, y) pairs
- unsupervised learning: Take x alone
- Why bother?
- Find most relevant features
- Compress information
- Retrieve similar objects
- Generate new data samples
- Explore high-dimensional data
- Autoencoders
- Compress data
- Dimensionality reduction
More Autoencoders
- Sparse autoencoder
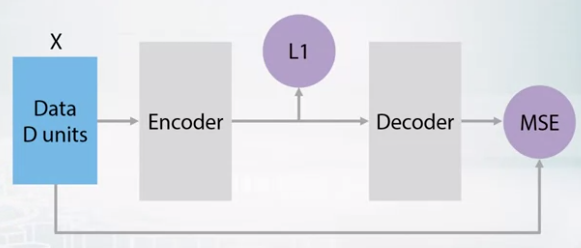
- Add some kind of L1 balance.
- Redundant autoencoder
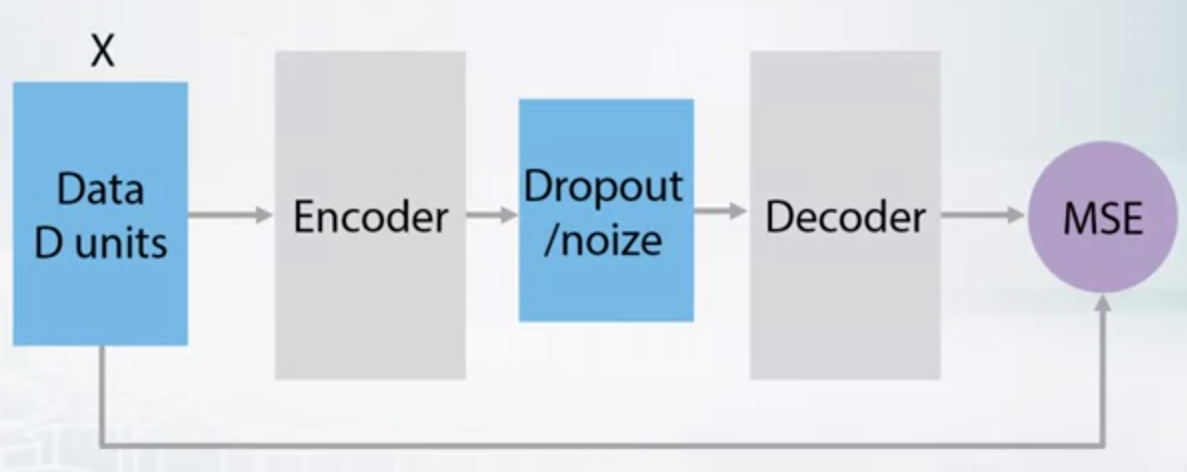
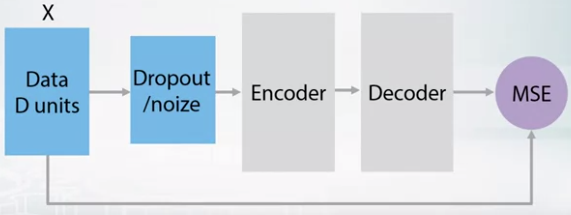
- Denoizing autoencoder
- Sparse VS Denoizing
- Sparse AE get sparse representation.
- Redundant AE get features that cover for one another
- Denoizing AE get some featrues that are able to extrapolate
- Image morphing with AE
- If we have a encoding value of 2 images, maybe average value for them can be semantic average of the 2 images.
- With decoder, you can generate image with it.
Word Embeddings
- Text 101: tokens
- Text: A sequence of tokens(words)
- Toekn/word: A sequence of character
- Character: An atomic element of text.
- Apply filtering first and then tokenization.
- bag of words
- count the number of words in article.
- ignores the word ordering
- Text Classification/Regression
- Adult content filter
- Detect age/gender/interests
- Text Classification: BoW + linear
- Get BoW for text
- Give word positive/negative weight for them
- Word Embeddings
- Embed word into small compact representation
- We can’t use MSE as image
- Want to make similar words to have similar representation
- Sparse vector products
- if we use 1 hot encoding, it’s unefficient since we have to calculate all words.
- Just calculate the row where the word class exist.
- Word2Vec
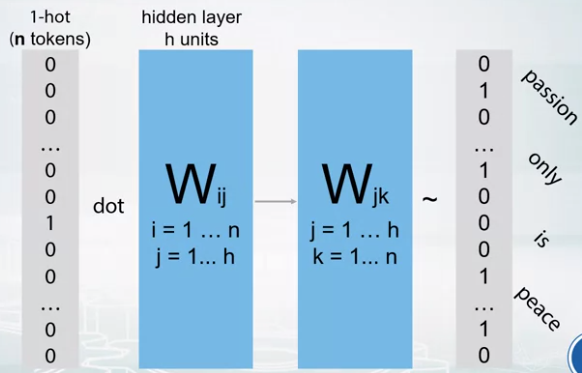
- First Matrix takes one-hot vector representation of one word.
- Row of matrix corresponds to the word vector
- Second Matrix user word vector to predict neighborhood.
- ex. we can give a word in the sentence as input and other words as the answer
- Calculation for right matrix is really heavy
- Softmax Problem
- Softmax layer after right matrix need to get all logits of classes in order to compute one output.
- More word embeddings
- Faster Softmax
- Alternative Models: GloVe
- Sentence level: Doc2vec
- Before GAN
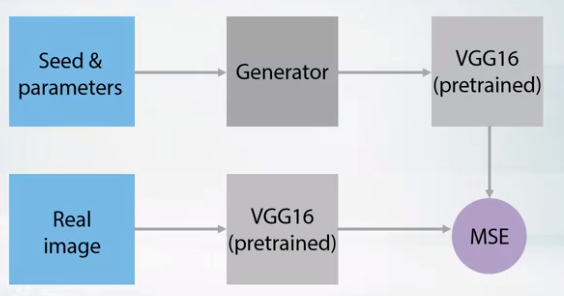
- It’s hard to use MSE for image generation. (Because MSE calculate loss as pixelwise function)
- So we use pre-trained nets for imageNet and get mean squared error of deep layer of 2 images.
- Generative Adversial Networks
- Generator
- Generate image with noise
- Discriminator
- Tell if image is plausible
- Step
- initialize generator and discriminator weights at random
- train discriminator on to classify actual images against images generated by untrained generator
- train generator to generate images that fool discriminator into believing they’re real
- train discriminator again on images generated by updated generator
- Generator
- Adversarial domain adaptation
- two domains
- ex. mnist digits vs actual digits on photos
- mnist are labeled but latter are not.
- two domains
- Domain adaptation
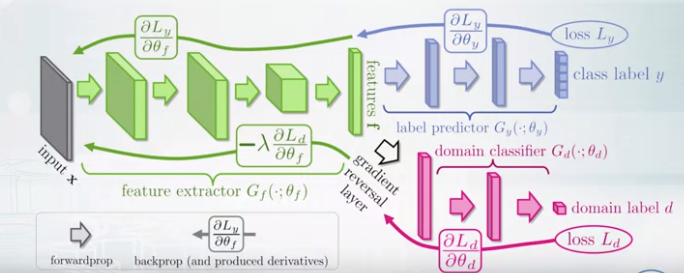
- Train the whole model back propagation with labeled data. (purple color)
- Prevent overfitting, like pink color train with new domain.
- Art style transfer
- Get the style feature from image, not content.
- Get filters of not too deep layer from pre-trained model.
- Use deeper layer for containing contents.
- https://harishnarayanan.org/writing/artistic-style-transfer/
Leave a comment