
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks (1506.01497v3)
Abstract
기존의 state of the art network에서는 RPN(Region Proposal Network)을 사용하여 물체의 위치를 찾아내었다. 기존의 SPPnet이나 Fast R-CNN은 Region proposal 계산에서 bottleneck 현상이 일어났다. 이 논문에서는 RPN이 detection network와 full image convolutional features 를 공유함으로써 region proposal에서 시간을 줄일 수 있게 함을 보인다. RPN이 object bounds와 object score를 동시에 계산해낸다. RPN과 Fast RCNN의 convolutional feature를 공유함으로써 하나의 네트워크로 묶는다.
Introduction
Object Detection은 Region Proposal method와 Region based convolutional netwrok 두가지로 이루어진다.
- 기존의 Region Proposal method
- Selective Search : Greedily merges superpixels based on low-level feature. 2 seconds per image
- EdgeBoxes : 0.2 seconds per image
이 논문에서는 Region proposal을 Deep CNN을 이용하여 구한다. Fast R-CNN에서 사용한 Region-Based detector의 convolutional feature map은 Region proposal을 구하는데도 사용이 가능하다. 이를 이용하여 우리는 그 네트워크 뒤에 몇 layer들을 만들어 동시에 region bounds를 regress하면서 objectness score를 계산해낼 것이다. RPN 네트워크는 기존에 image의 크기를 바꾸거나 filter의 크기를 바꾸는 것과 달리 anchor box라는 개념을 도입하여 running speed를 개선하였다.
Related Work
- Object Proposals
- Grouping super-pixels (Selective Search, etc)
- Based on Sliding-windows (EdgeBoxes)
- Deep Networks for Object Detection
- R-CNN에서 사용한 방법에서는 proposal region을 object인지 bg인지 구분해낸다. 하지만 Object Bound를 안잡아내므로 Region proposal module에 따라 영향을 많이 받는다.
- Overfeat에서 사용한 방식에서는 Fully-connected layer가 box coordinate를 예측해내도록 학습한다.
- MultiBox에서는 class-agnostic boxes를 이용하여 위치만 탐지한다. 이때, proposal과 detection network 간에 feature를 공유하지는 않는다.
Faster R-CNN
Faster R-CNN 은 크게 2개의 모듈로 나뉜다. 첫 모듈은 Deep Fully convolutional Network로 Region Proposal을 한다. 그리고 다른 하나는 Fast R-CNN Detector로 Proposed Region내에서 object를 판별한다.
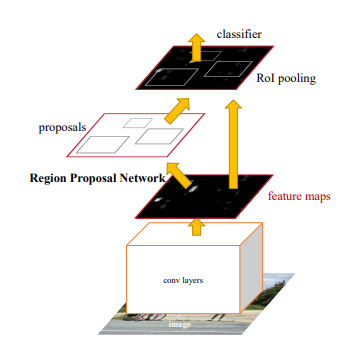
이 두가지 모듈이 하나의 네트워크로 구성되어 있고 이는 ‘attention’ 메커니즘을 사용하여 RPN 모듈이 Fast R-CNN 모듈에게 어디를 보라고 알려주는 것이다.
- RPN input : 이미지 output : set of rectangular object proposals with objectness score Region Proposals들을 generate하기 위해 feature map의 output에 small network를 slide한다. 이 feature들은 box regression layer과 box classification layer에 공급된다. Sliding window의 각 location 마다 multiple region proposals들을 계산한다. Reg Layer에서는 4k output을 갖게 되고 (coordinates * k), classification layer에서는 2k output을 갖게된다. (Object와 Non object인지 각각 확률). 이때 k는 anchor를 의미한다.
- Translation Invariant Anchor MultiBox에서는 k-means 알고리즘을 사용하여 800개의 anchors를 만든다. 따라서 물체의 위치가 달라지면 새롭게 anchors들을 만들어내야 한다. 하지만 이 논문에서 채택한 방식에 따르면 Translation-invariant property를 갖게 된다. 이는 image에서 하나의 물체를 찾아내었다면 그 물체가 다른 곳에 움직이더라도 똑같이 물체로 인식하게 되는것이다. 또한 이런 방식은 model size를 줄여주게 되고 이는 overfitting을 방지하는데 도움이 된다. 이 논문에서 제안한 방식대로 하자면 Proposal layers의 parameter 개수는 3 * 3 * 512 * 512 + 512 * 6 * 9가 된다. 논문에서 VGG 16네트워크를 feature map으로 사용한 경우, RPN에서는 3 * 3 window를 512개의 filters 별로 각각 conv 동작을 수행하여 사용한다. 이때 이 값들별로 coordinates와 object or non object인지 값 ( 4 + 2) 와 anchors의 개수 ( 9 ) 를 곱해준 512 * 6 * 9의 parameter 개수를 갖는다. 그리고 3 * 3 conv를 해주면서 이 conv layer에 parameter들이 존재하는데 이 개수는 filter 개수 * conv layer의 size * 다음 이 conv 에서 FC layer에 값으로 전해주는 개수인 3 * 3 * 512 * 512가 나오게 된다.
- Multi-Scale Anchors as Regression References 논문 이전에는 image / feature pyramid 를 이용하여 multiple scale들을 해주었다. 또 다른 방식으로는 여러 scale을 여러 크기의 sliding windows들을 사용하는 것이였다. (pyramid of filters라고 생각할 수 있다.) 본 논문에서는 Anchor-based model을 사용하는데 pyramid of anchors라고 볼 수 있다. filter size는 하나로 고정되고 anchor의 scale과 ratio를 다양하게 사용하여 학습시킨다.
- Loss Function
RPN을 학습시키기 위해서 우리는 Binary Class label을 사용한다. 이때, 다음과 같은 2경우에 positive label을 준다.
1) Highest IoU overlap with a ground-truth box를 가진 anchor
2) Gorund Truth Box 와 IoU 가 0.7 이상인 모든 anchors
1의 조건은 2의 조건이 하나도 없는 경우를 방지하기 위해 넣어준다. IoU ratio가 모든 ground truth boxes와 0.3 이하면 negative를 assign해준다. Negative, Positive 둘다 assign 되지 않은 경우, 학습에 영향을 주지 않는다.
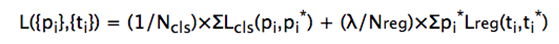
Loss Function 은 위의 식과 같다. i는 index of an anchor in minibatch, pi는 anchor i 가 object로 추측된 확률, pi_star는 ground truth이다. ti는 bounding box의 coordinates를 예측한 vector이다. ti_star는 ground truth의 positive anchor과 연관된 ground-truth box의 coordinates이다. Lcls는 classification loss로, log loss over two classes이다. (object vs not object) LregRobust loss function을 사용한다. 이때, regression loss는 positive ground truth 에서만 계산이 되도록 pi_star를 앞에 붙여준다. Ncls는 mini-batch의 size를 의미하고 Nreg는 anchor location의 개수를 의미한다. 이때, classification과 regression loss간의 균형을 맞추기 위해 람다값 10을 넣어준다. 기존의 RoI based method에서는 bounding box regression은 랜덤한 size의 ROI에서 pooled된 feature들을 이용한다. 이 논문에서 제안한 방식에서는 features들의 사이즈는 같고, 여러 사이즈들을 위해 k개의 regressor들이 학습을 하며 이 regressor들은 서로의 무게를 공유하지 않는다. - Training RPNs Back propagation과 SGD(Stochastic gradient descent)를 이용하여 학습이 가능하다. 한 이미지의 모든 anchor에서 loss function을 opitmize하는 것은 가능하지만, negative sample이 dominate해버리므로 하나의 이미지에서 256개의 sample들을 랜덤하게 만들어 mini batch로 만든다. 이때의 sample들은 1대1의 positive, negative 비율이 갖게 만드낟. 학습시, 모든 새로운 layer들은 randomly initialize하고 zero-mean gaussian distribution을 따르게 한다. 다른 layer들(Feature Map Layer)들은 imagenet classification 모델의 무게값을 가져온다.
- Sharing Featrues for RPN and Fast R-CNN
RPN과 Fast R-CNN이 각각 학습을 하면서 convolutional layer를 다른 방식으로 변경할 것이다. 그래서 이 논문에서는 이렇게 공유하는 convolutional layer를 잘 학습시킬 수 있는 방식을 개선했다. 이 논문에서는 3가지 방식을 제안하였다.
- Alternating training RPN을 우선적으로 학습시킨후 proposal들을 이용하여 Fast R-CNNㅇ르 학습시킨다. 이렇게 tuned된 Fast R-CNN을 시작하는데 다시 사용된다.
- Approximate Joint Training RPN과 Fast R-CNN이 하나의 네트워크로 합쳐져 한번에 학습된다. 매 SGD iteration에서 forward pass 가 region proposal들을 생성해내고 이를 Fast R-CNN은 이 값을 이용하여 학습한다. Backward propagation에서 shared layer는 RPN loss와 Fast R-CNN loss 모두 받게 된다. 이런 방법은 구현은 쉬우나 proposal box의 coordinates 또한 network에서 파생된 결과이므로 정확한 ground truth가 아니다.
- Non Approximate Joint Training RPN의 결과값이 Fast R-CNN 부분의 input으로 들어간다. ROI Pooling layer는 전체 이미지에서 box coordinates 들을 구별해낸다.
- 4-Step Alternating Training
1) Pretrained된 ImageNet 모델을 이용하여 RPN을 학습시킨다.
2) 1을 통해 학습된 RPN에서 나온 Region Proposal을 이용하여 네트워크를 학습시킨다. 이 detection network또한 Imagenet으로 pretrained되어 있는 것을 사용한다.
3) shared layer는 freeze하고 RPN을 다시 학습시킨다.
4) shared layer를 프리징한 상태로 Fast R-CNN layer를 학습시킨다.
Leave a comment